最近学到了一个新鲜玩意,Python网页爬取数据脚本,今天我们就来试一试,python爬取数据到底有多方便。
下面直接放源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| from selenium import webdriver
from urllib import request
import re
import os
import datetime
print(datetime.datetime.now())
filedir = "d:\\tsldrb_pic\\"
if not os.path.exists(filedir):
os.makedirs(filedir)
f = open("d:\\urls.txt", "r", encoding='utf-8')
urls = f.readlines()
for url in urls:
print(url.replace('\n', ''))
driver = webdriver.Chrome()
driver.maximize_window()
driver.get(url)
data_content = request.urlopen(url.replace('\n', ''))
content_text = data_content.read().decode()
result_title_time = re.search('(?<=content/).*(?=/content)', url.replace('\n', ''))
result_title = re.search('(?<=">).*(?=</h2)', content_text)
result_title_time.group().replace('/', '')
pic_name = result_title_time.group().replace('/', '') + result_title.group().replace(' ', '') + '.png'
driver.get_screenshot_as_file(filedir + pic_name)
driver.close()
print(datetime.datetime.now())
|
使用教程:
打开此电脑,随便到哪个目录新创一个txt文件,例如我这里使用的是E盘:

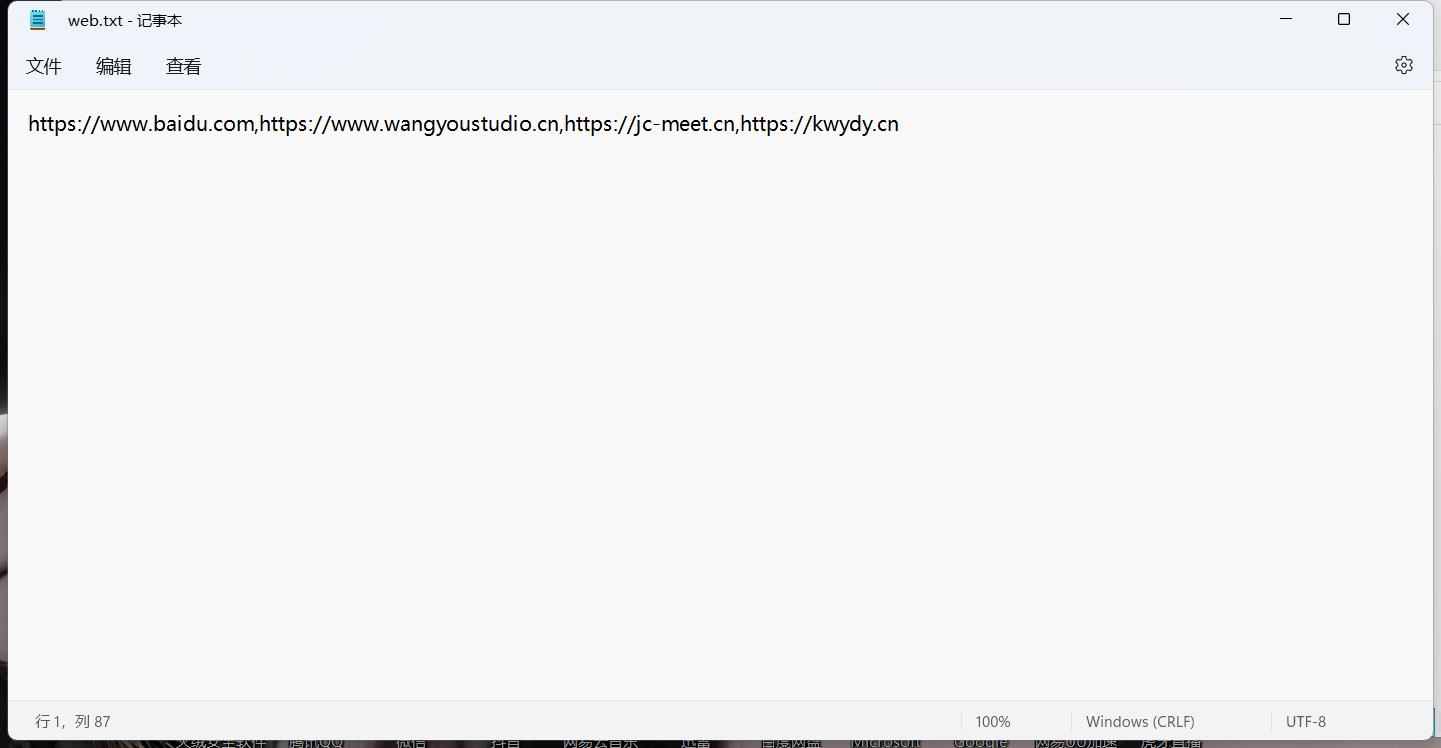
创建完之后在里面输入多个网址,并用“,”隔开:
另外下载pycharm,复制代码即可完成爬取txt文档里的多个网页数据。